数据采集 ETL 工具 Elasticsearch-datatran v6.5.8发布
Elasticsearch-datatran v6.5.8 功能改进
数据同步改进:采用外部数据源管理增量状态时,停止作业后重启作业失败问题处理
数据同步改进:优化同时向多个elasticsearch写入数据功能
数据同步改进:优化sqlite增量管理机制
优化IP地址解析性能
改进批量bulk操作filter_path配置,默认不设置filter_path,如果需要设置,可以参考文档中涉及批处理内容
https://esdoc.bbossgroups.com/#/document-crud
https://esdoc.bbossgroups.com/#/bulkProcessor
数据同步改进:JobTaskMetrics和TaskMetrics增加lastValue属性,用于存放任务执行完毕后的增量状态
数据同步改进:增加elasticsearch数据同步到自定义处理器功能
增加增加elasticsearch数据同步到redis案例(批处理和单条处理)
全局属性改进:增加属性配置解析拦截器PropertiesInterceptor,通过PropertiesInterceptor对加载后的属性值进行自定义处理,比如加密属性解密处理
优化属性配置变量解析机制
Elasticsearch-datatran特色
Elasticsearch-datatran 由 bboss 开源的数据采集同步ETL工具,提供数据采集、数据清洗转换处理和数据入库功能。支持在Elasticsearch、关系数据库(mysql,oracle,db2,sqlserver、达梦等)、Mongodb、HBase、Hive、Kafka、文本文件、excel文件、SFTP/FTP多种数据源之间进行海量数据采集同步;支持数据实时增量采集和全量采集;支持根据字段进行数据记录切割;支持多级文件路径信息将不同文件数据写入不同的数据库表。
提供自定义处理采集数据功能,可以按照自己的要求将采集的数据处理到目的地,如需定制化将数据保存到特定的地方,可自行实现CustomOutPut接口处理即可。
Elasticsearch-datatran 的独特之处,其数据同步作业采用java语言开发,小巧而精致,可以用采用java提供的所有功能和现有组件框架,随心所欲地处理和加工海量存量数据、实时增量数据;可以根据数据规模及同步性能要求,按需配置和调整数据采集同步作业所需内存、工作线程、线程队列大小;可以将作业独立运行,亦可以将作业嵌入基于java开发的各种应用汇总运行;提供了作业任务监控api、作业启动和停止api,可轻松定制一款属于自己的ETL管理工具。
如果您还在苦于logstash、flume、filebeat之类的开源工具无法满足复杂的、海量的数据处理加工场景,那么Elasticsearch-datatran将是一个不错的选择。
Elasticsearch版本兼容性:支持各种Elasticsearch版本(1.x,2.x,5.x,6.x,7.x,8.x+)之间相互数据迁移
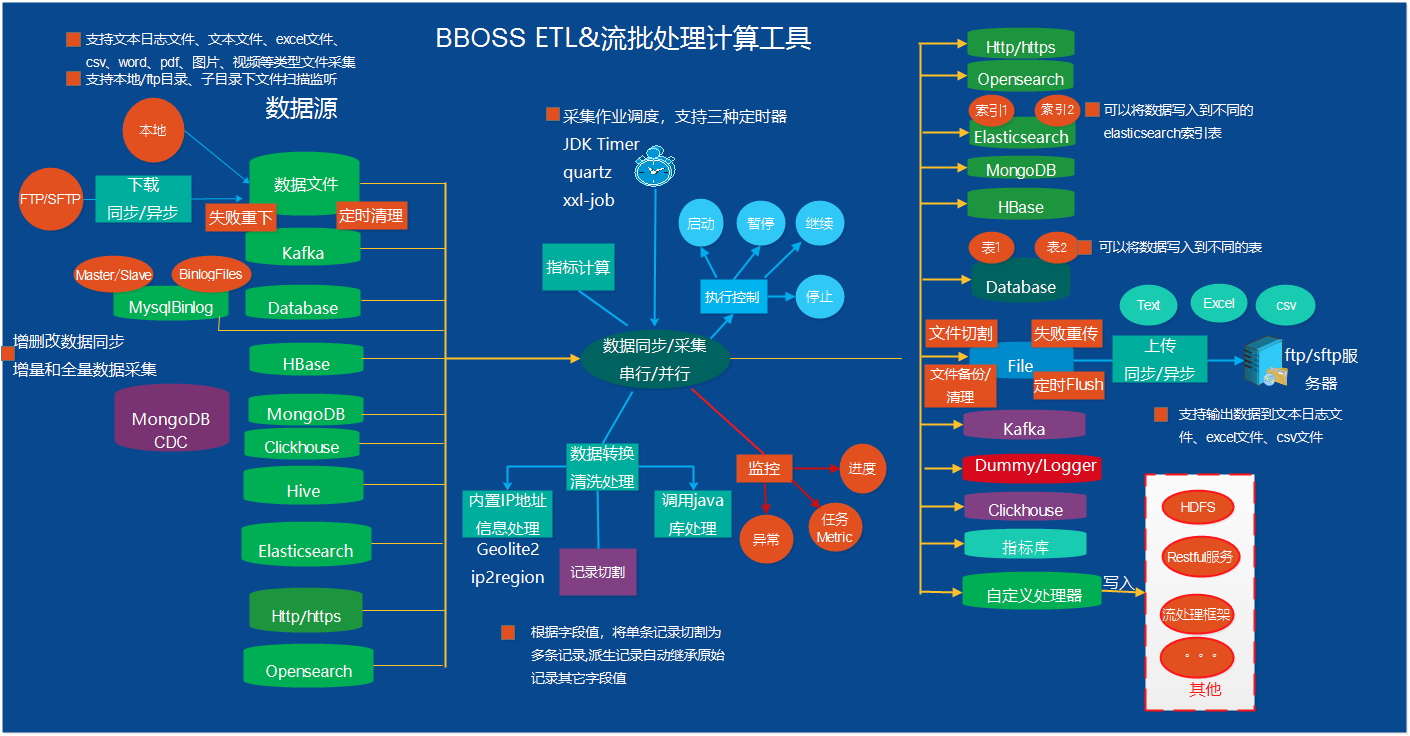
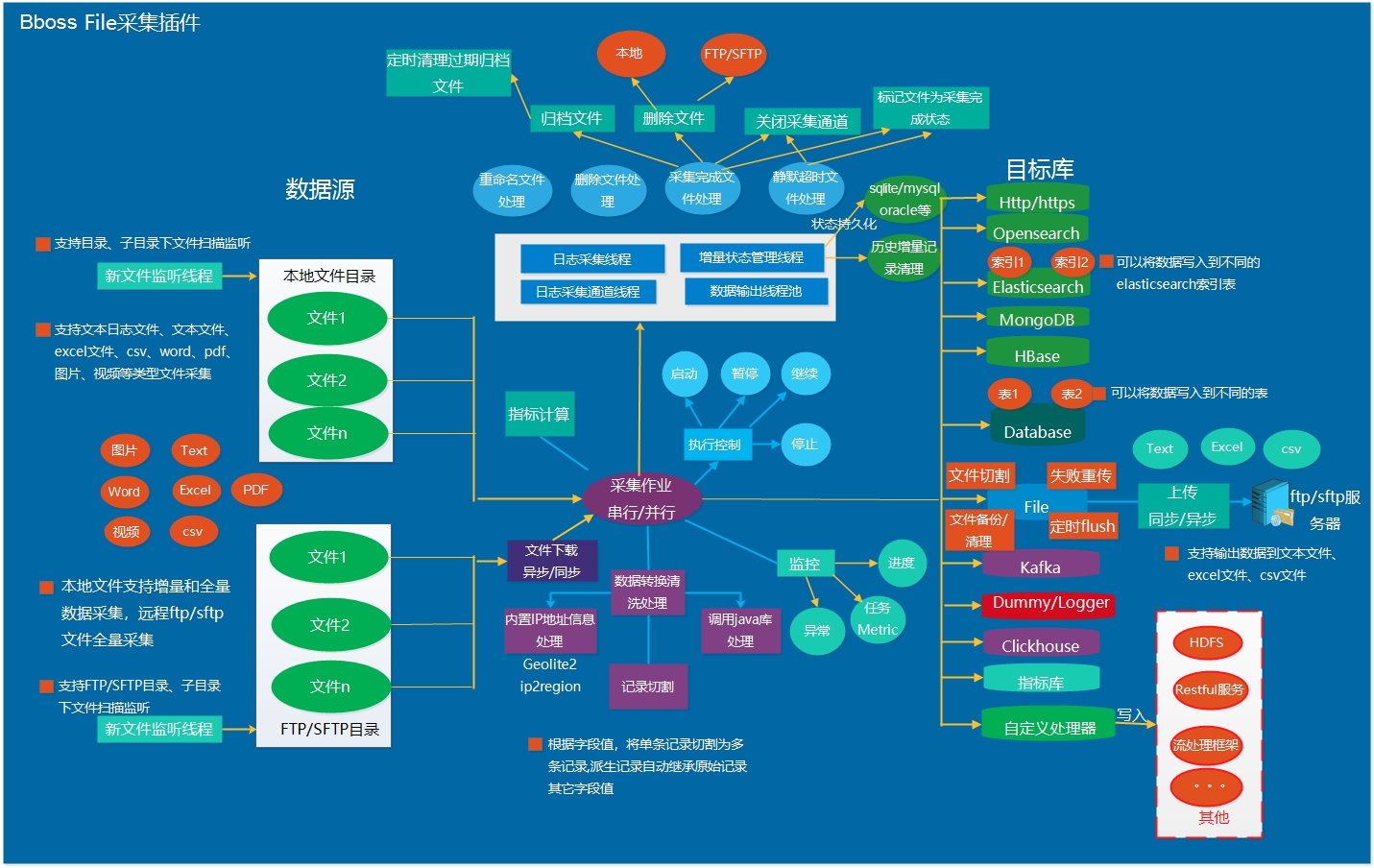
功能完备的文件数据采集插件:支持从ftp/sftp并行下载各种文件,并行采集和处理各种文件数据
bboss案例大全
https://esdoc.bbossgroups.com/#/bboss-datasyn-demo
Quick Start
https://esdoc.bbossgroups.com/#/quickstart